1. Introduction
In this tutorial, we’ll discuss the core concepts of Kafka. Understanding these core concepts is important for having strong understanding Kafka.
2. Messages and Batches
In Kafka, the unit of data is called a message. You can think of a message as a row in a database. A message in Kafka is simply an array of bytes and nothing more than that for the Kafka. A message can include an optional piece of metadata, known as a key.
Like the message, key is also an array of byte and no specific meaning to the Kafka. Keys are used in writing messages to the partitions in a controlled manner. The simplest scheme is to generate a hash of the key and then selecting the partition number for that message by taking the hash result modulo the total number of partitions in the topic. This ensures that messages with the same key are always written to the same partition, provided the partition count remains unchanged.
For efficiency, messages are written into Kafka in batches. A batch is simply a collection of messages that are all being produced to the same topic and partition.
3. Schemas
For Kafka, message is just an array of bytes. A consistent data format is important in Kafka and therefore it is recommended that you use a schema for the message based on the application needs.
The common formats are JSON and XML. Many Kafka developers favor Apache Avro. There are many advantages of Avro which you can check in the official documentation. Few are compact serialization format and schemas that are separate from the message payloads. By providing a consistent format, reading and writing of messages can be decoupled.
4. Topics and Partitions
Messages in Kafka are categorized into topics. You can think of topics as tables in databases. A database table has logically similar records. Topics are further broken down into partitions. Messages are appended to it sequentially and are read in order from the beginning to the end. Note that since a topic typically has multiple partitions, there is no guarantee of message ordering across the entire topic. Message ordering is ensured within the single partition.
Following figure shows a topic with three partitions:
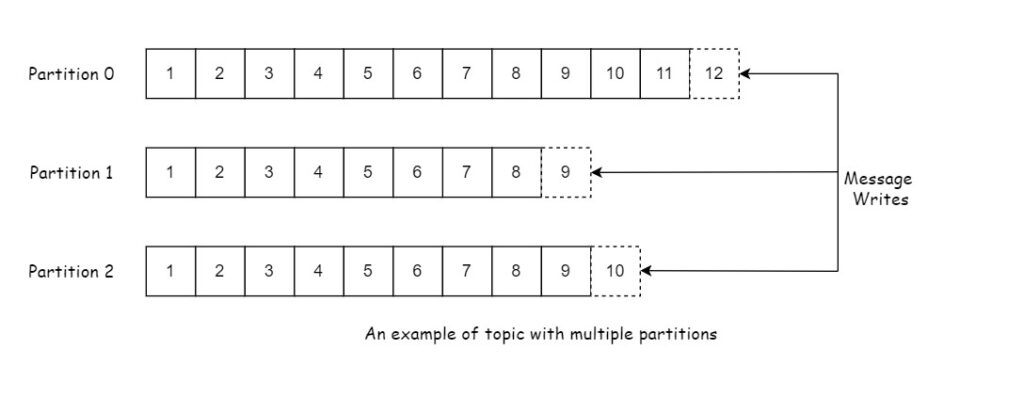
Kafka uses partitions to provide scalability and redundancy. Each parition can be hosted on a different server which provide better performance in comparison to a single server. A copy of a partition can be replicated on different servers to provide redundancy.
Kafka does not decide for us the number of partitions. It is a design decision. When we create a topic, we have to decide the number of partitions.
5. Streams in Kafka
A stream in Kafka is considered data of a single topic irrespective of the number of partitions.
6. Producers and Consumers
In Kafka, Producers create new messages. Messages are produced to a specific topic. By default, the messages will be produced to a specific topic. By default, the producer will distribute messages evenly across all partitions of a topic. In certain situations, the producer will send messages to specific partitions. This is usually accomplished by using the message key along with a partitioner, which generates a hash of the key and maps it to a specific partition. This guarantees that all messages with a given key are written to the same partition.
Consumers read messages. In other publish/subscribe systems, these clients are often referred to as subscribers or readers. The consumer subscribes to one or more topics and reads the messages in the order they were produced within each partition. The consumer keeps track of which messages it has already consumed by keeping track of the offset of messages. The offset—an ever-increasing integer value—is another piece of metadata that Kafka appends to each message when it is produced. Each message in a given partition has a unique offset, with subsequent messages having higher offsets (though not necessarily consecutively higher). By storing the next possible offset for each partition a consumer can stop and restart without losing its place.
Consumer is a part of a consumer group. A consumer group is one or more consumers that work together to consumer a topic. The group ensures that each partition is only consumed by one member. It is possible that that a consumer works upon two partitions. The assignment of a consumer to a partition is often referred to as the consumer’s ownership of the partition. When one consumer fails the other consumer can take its place to work upon the partition.
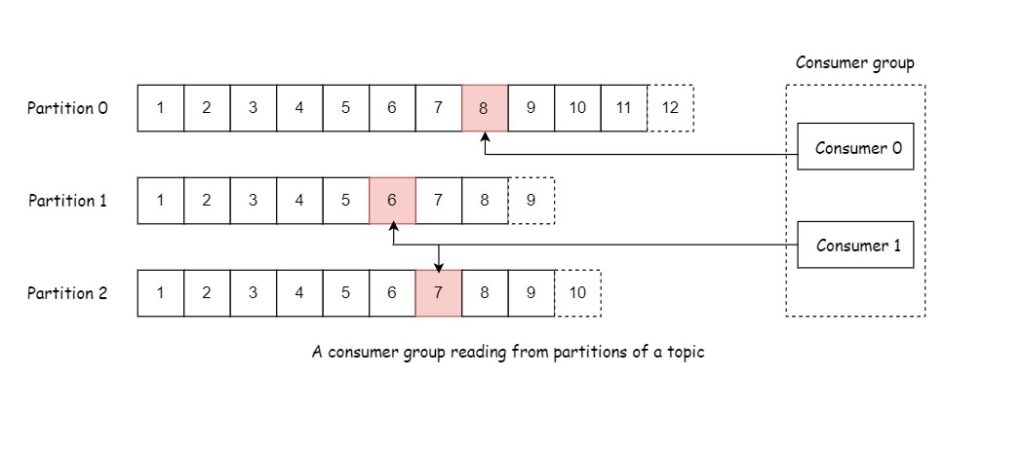
In Kafka Producers and Consumers are decoupled. Producers are not concerned who is consuming the data.
7. Brokers and clusters
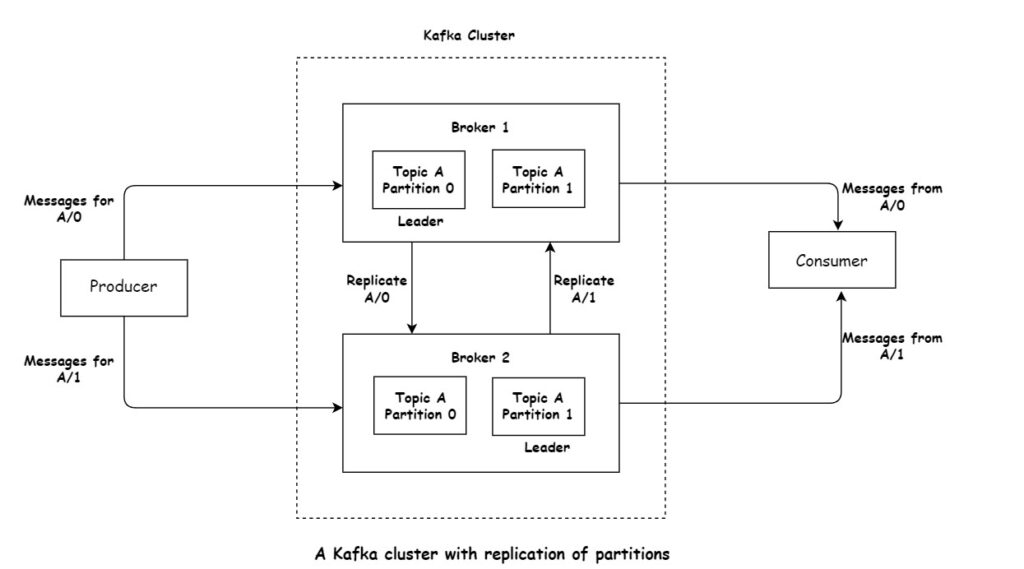
An individual Kafka server is known as a broker. The broker receives messages from producers, assigns offsets to them, and writes the messages to disk storage. Additionally, it caters to consumers, processing their requests for partition data and providing the corresponding published messages. A single broker can effortlessly handle thousands of partitions and millions of messages per second, depending on hardware capabilities.
Kafka brokers are designed to operate as part of a cluster. One broker within a cluster assumes the role of cluster controller, dynamically chosen from active members. The controller fulfills administrative duties within the cluster, such as allocating partitions to brokers and overseeing broker health. Within a cluster, a partition is exclusively controlled by one broker, referred to as the partition leader. To enhance fault tolerance, replicated partitions are assigned to additional brokers, termed followers. Producers must interact with the partition leader to publish messages, while consumers can fetch from either the leader or a follower.
8. Message retention
A core feature of Apache Kafka is its ability to durably store messages for a configurable duration. Kafka brokers are configured with a default retention setting for topics, either retaining messages for some period of time (e.g., 7 days) or until the partition reaches a certain size in bytes (e.g., 2 GB). Once these limits are reached, messages are expired and deleted. For granular control over data retention, Kafka allows topic-level configuration of message expiration. To optimize storage for topics where the latest value is crucial, topics can be configured as log compacted, retaining only the most recent message for each unique key.
9. Multiple clusters
As Kafka deployments expand, it is often beneficial to have multiple clusters. When having multiple datacenters, it is often required that messages be copied between them. By doing so, the consumers are able to get the latest information by connecting any of the datacenters. The replication mechanisms within Kafka clusters are designed to operate only within a single cluster, not across multiple clusters.
The Kafka project includes a tool called MirrorMaker, which is used for replicating data across different clusters. Essentially, MirrorMaker functions as a Kafka consumer and producer connected by a queue. It consumes messages from one Kafka cluster and produces them to another.
10. Conclusion
Understanding Apache Kafka’s core concepts is essential for building robust and scalable real-time data pipelines. By grasping the fundamentals of topics, partitions, producers, consumers, and offsets, you’ve laid a strong groundwork for leveraging Kafka’s capabilities.