1. Introduction
In this tutorial, we’ll discuss Kubernetes fundamental concepts and components.
2. Kubernetes cluster
A Kubernetes cluster is a set of nodes, or machines, that run containerized applications managed by Kubernetes. A node provides CPU memory, other resources for use by applications.
Kubernetes supports two node types:
- Master node (Control plane nodes)
- Worker nodes
Both types can be physical servers, virtual machines, or cloud instances. Both of these nodes can run on ARM and AMD64/x86-64. Control plane nodes must be Linux, but worker nodes can be Linux or Windows. A single Kubernetes cluster can have a mix of Linux and Windows worker nodes, and Kubernetes is intelligent enough to schedule apps to the correct nodes. Every cluster needs at least one ‘Control plane’ node, however it is recommended to have at least three or five nodes spread across availability zones for high availability.
In a Kubernetes cluster, each control plane node is responsible for running all critical control plane services. These services include the API server, scheduler, and various controllers, which work together to manage the entire cluster and ensure applications run smoothly.
Worker nodes are dedicated to running user applications within a Kubernetes cluster.
It’s common to run user applications on control plan nodes in development and test environments. Control plane nodes are capable of running user applications; however, in production environments, it’s generally best to restrict user applications to worker nodes. This ensures that control plane nodes can focus exclusively on managing cluster operations.
3. The control plane
In Kubernetes, the control plane is the central component responsible for managing the overall state and operation of the cluster. It serves as the brain of Kubernetes, orchestrating and coordinating all activities, including scheduling applications, scaling, self-healing, and implementing desired configurations. The control plane ensures that the cluster functions as intended by monitoring and managing the health and status of both applications and nodes.
Key components of the control plane are API server, scheduler, controller manager, etcd, cloud control manager. Most clusters run every control plane service on every control plane node for HA. Let us now discuss the services of the control plane:
3.1 The API server
The API server is the primary interface for all interactions with the cluster. It receives requests from users, external services, and internal components, and acts as a communication hub for the cluster. Even internal control plane services communicate with each other via the API server. It exposes a RESTful API over HTTPS, and all requests are subject to authentication and authorization. For example, deploying or updating an app follows this process:
- Describe the requirements in a YAML configuration file
- Post the configuration file to the API server
- The request will be authenticated and authorized
- The updates will be persisted in the cluster store
- The updates will be scheduled to the cluster
3.2 The cluster store
The cluster store maintains the desired state of all applications and cluster components. The cluster store is the only stateful element of the control plane. It’s based on the etcd distributed database, and most Kubernetes clusters run an etcd replica on every control plane node for HA. For large clusters with frequent changes, a separate etcd cluster may be used to enhance performance. For optimal availability, etcd prefers an odd number of replicas to prevent split-brain scenarios.
Split-brain scenario
A split-brain scenario is a situation in distributed systems where network or communication failures cause a cluster to split into isolated parts, each operating independently. In this scenario, two or more segments of the system might each believe they are the “primary” or “active” segment, leading to conflicting decisions or data inconsistencies.
In the context of databases like etcd, split-brain can result in:
- Data Inconsistency: Each partition might write or read different data, leading to conflicting states.
- System Instability: The system might perform duplicate or conflicting actions, which can lead to errors or downtime.
Using an odd number of replicas in clusters (often three or five) helps prevent split-brain by allowing the system to achieve a quorum or majority consensus on the “true” state, even if one replica becomes isolated. This design ensures the cluster continues to operate accurately despite partial failures.
Following figure illustrates two etcd setups facing a network split. The left cluster, with four nodes, is split evenly (two nodes each) without a majority, causing a split-brain. The right cluster, with three nodes, avoids split-brain as Node A lacks a majority, while Nodes B and C hold the majority and continue operating.
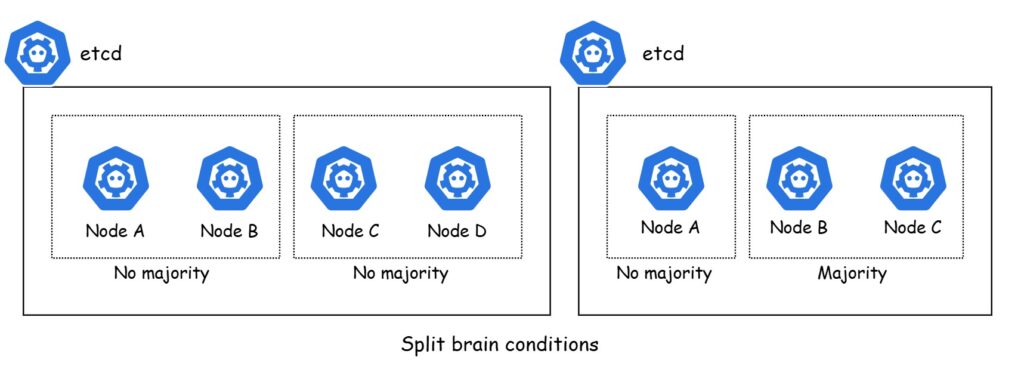
In a split-brain scenario, etcd switches to read-only mode, blocking cluster updates while allowing user applications to continue running. Consistent writes are essential, and etcd uses the RAFT consensus algorithm to handle multiple write requests safely.
3.3 Controllers and the controller manager
Kubernetes controllers are components that continuously monitor the state of the cluster, ensuring it aligns with the desired configurations. They work to ensure that applications, resources, and services in the cluster are running as expected. Controller Manager is the component that runs these controllers in the Kubernetes control plane.
Controllers run on the control plane, and some of the more common ones include:
- The Deployment controller
- The StatefulSet controller
- The ReplicaSet controller
Controllers operate as background watch loops, continuously aligning the observed state with the desired state. Controller manager that is responsible for spawning and managing the individual controllers.
3.4 The scheduler
The scheduler monitors the API server for incoming tasks and allocates them to available, healthy worker nodes. The process includes:
- Monitoring the API server for new tasks.
- Identifying nodes that are capable of handling the tasks.
- Assigning tasks to these capable nodes.
The scheduler skips unsuitable nodes and ranks the others based on factors like existing images, available CPU and memory, and the number of current tasks. If the scheduler can’t find a suitable node, it marks tasks as pending. In clusters set up for autoscaling, these pending tasks trigger an autoscaling event, which adds a new node and schedules the tasks on it.
3.5 The cloud controller manager
The Kubernetes Cloud Controller Manager (CCM) is a key component in Kubernetes architecture that integrates cloud-specific control logic. It allows you to link your Kubernetes cluster with your cloud provider’s API to manage cloud resources effectively. The CCM includes controllers for tasks such as:
- Node Controller: Monitors the state of the nodes in the cloud, ensuring they are in sync with the Kubernetes API.
- Route Controller: Manages network routes in the cloud environment.
- Service Controller: Creates, updates, and deletes cloud provider load balancers.
By decoupling cloud-specific logic from the core Kubernetes components, the CCM provides a more modular and cloud-agnostic design, enhancing Kubernetes’ ability to work across different cloud environments.
4. Worker nodes
In Kubernetes, worker nodes (also known simply as nodes) are the machines where your application workloads run. Each worker node hosts Pods, which are the smallest units of deployment in Kubernetes.
Let’s look at the major worker node components.
4.1 Kubelet
The kubelet is the primary Kubernetes agent responsible for communication with the cluster. Its key functions include:
- Monitoring the API server for new tasks.
- Directing the appropriate runtime to execute tasks.
- Reporting the status of tasks to the API server.
If a task cannot be executed, the kubelet informs the API server, allowing the control plane to determine the next steps.
4.2 Runtime
In a Kubernetes worker node, the runtime refers to the container runtime that is responsible for managing the lifecycle of containers. Here’s what it entails:
- Starting Containers: The runtime pulls the necessary container images and starts containers based on the specifications provided in the Pod definition.
- Stopping Containers: It handles stopping and removing containers when they are no longer needed or when they need to be replaced.
- Managing Container State: The runtime monitors and maintains the state of the running containers, ensuring they are healthy and meet the required conditions.
4.3 Kube-proxy
In Kubernetes, kube-proxy is a network component that runs on each node and is responsible for maintaining network rules on nodes. These rules allow network communication to your Pods from network sessions inside or outside of your cluster. Here’s a rundown of its key roles:
- Service Discovery and Load Balancing: kube-proxy watches the Kubernetes API for Services and endpoints updates. It provides routing to correctly distribute traffic to available Pods.
- Network Traffic Management: It implements IP tables rules or IPVS to direct traffic to the correct Pod based on the service endpoints.
- Handling Network Changes: kube-proxy dynamically updates routing rules as the state of the cluster changes, ensuring traffic always reaches the right destinations.
By managing these network rules, kube-proxy ensures seamless communication between various components of the Kubernetes cluster, which is crucial for the proper functioning of applications deployed on Kubernetes.
5. kubectl
kubectl is the Kubernetes command-line tool.
It’s important that your kubectl version is no more than one minor version higher or lower than your cluster. For example, if your cluster is running Kubernetes 1.29.x, your kubectl should be no lower than 1.28.x and no higher than 1.30.x.
At a high level, kubectl translates user-friendly commands into HTTP REST requests and dispatches them to the API server. Behind the scenes, it reads a kubeconfig file to determine the target cluster and the necessary credentials.
The kubeconfig file is called config and lives in your home directory’s hidden .kube folder. It contains definitions for clusters, Users (credentials), Contexts.
Clusters is a list of Kubernetes clusters that kubectl knows about and allows a single kubectl installation to manage multiple clusters. Each cluster definition has a name, certificate info, and API server endpoint.
Users: This section contains a list of user credentials. For example, you could have a dev user and an ops user, each with distinct permissions. These user credentials are defined in the kubeconfig file and are identified by friendly names and their respective credentials. If X.509 certificates are used, the username and group information for Kubernetes are embedded within the certificate.
Contexts: In kubectl, contexts group clusters and users under a single, recognizable name. For instance, you might have a context named ops-prod that links the ops user credentials with the prod cluster. When you use kubectl with this context, it directs commands to the API server of the prod cluster, authenticating as the ops user.
Following are some important commands:
kubectl config view: command to view your kubeconfigkubectl config current-context: command to see your current context.kubectl config use-context: command to change current context