1. Introduction
In this tutorial, we’ll briefly introduce the Kafka. We’ll discuss the publish/subscribe messaging and also the problems which Kafka solves.
2. Publish/Subscribe Messaging
Before discussing the Kafka, it is important to understand the concept of publish/subscribe messaging and its importance for data-driven applications.
It is common for an enterprise application to generate lot of data by different sub-systems. For example, an enterprise application has different servers for different purposes, frontend server, database server, application server, other third party server etc. All these servers generate different types of data. Now suppose you have a monitoring services which collects data from these services and shows on the dashboard. The example of such services are active monitoring services, database monitor service and metrics analysis service. These service connect to these services to get the data and display on the dashboard. Following figure shows this architecture:
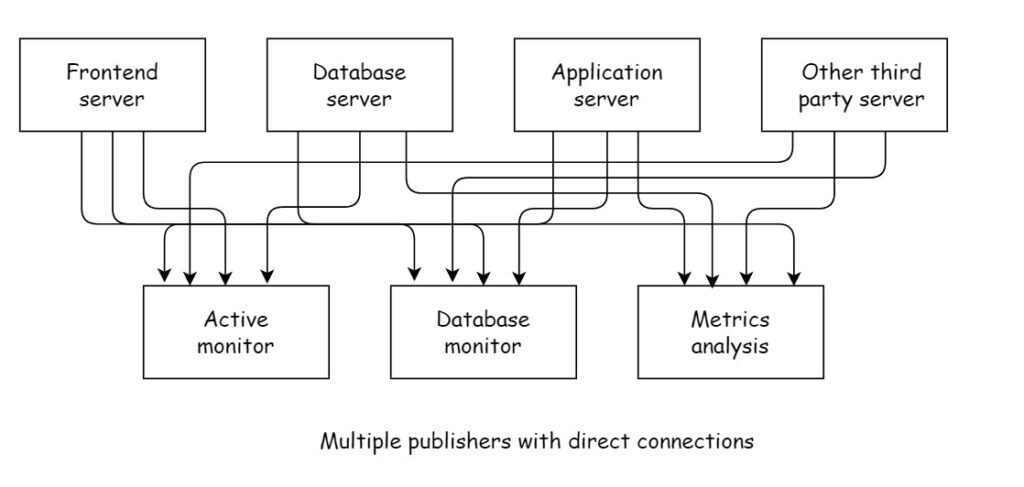
As you can see this architecture is difficult to maintain. This system becomes more complex with the introduction of new systems.
To solve this problem, you can introduce a pub/sub system. Following diagram shows this architecture:
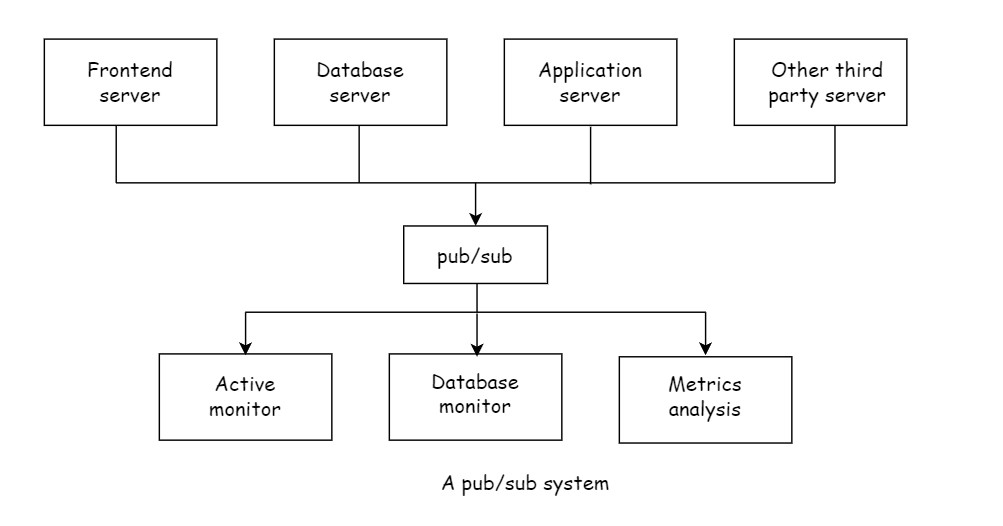
In a Publish/subscribe (pub/sub) messaging pattern, sender (publisher) of a piece of data (message) does not send message directly to the receiver. The receiver(subscriber) subscribes to receive certain classes of messages. In a pub/sub system, most often there is a central point (called a broker) where messages are published and subscribed.
3. Kafka
Kafka is an open-source distributed event streaming platform. Kafka is a highly scalable, and distributed platform for creating and processing streams in real-time.
Apache Kafka was developed as a publish/subscribe messaging system to solve the earlier described problem. It is often described as a “distributed commit log” or a “distributing streaming platform.”
A filesystem or database commit log is crafted to maintain a persistent record of every transaction, allowing them to be replayed to reliably reconstruct the system’s state. Similarly, data in Kafka is stored in a durable and ordered manner, allowing it to be read deterministically. Additionally, the data can be distributed across the system, offering enhanced protection against failures and significant opportunities for scaling performance.
4. Why Kafka?
There are many publish/subscribe messaging systems available to choose. Let us discuss reasons to choose Kafka.
- Multiple Producers: Kafka can efficiently manage multiple producers, whether they are using different topics or the same topic.
- Multiple Consumers: Kafka is designed to handle multiple consumers reading from the same stream of messages simultaneously, without causing interference between clients. This differs from many queuing systems, where a message is only available to one client after being consumed. In Kafka, multiple consumers can work as part of a group, sharing a stream and ensuring that each message is processed only once by the group as a whole.
- Retention: Kafka allows message retention and therefore you don’t have to work with messages real time. Retention rules are configurable. Messages are written to the disk. This is helpful when the consumers are slow to consume the messages or fail. Consumers can be stopped and restarted later to resume the consumption of messages.
- Scalable: Kafka is scalable. You can start with a single broker and scale to even hundreds of brokers based on the requirement. Expansions can be carried out while the cluster remains online, ensuring no impact on the overall system’s availability.
- High Performance: Kafka is renowned for its exceptional performance. It can handle massive volumes of data with low latency.
5. Uses of Kafka
5.1 Activity tracking
Kafka was originaly designed at LinkedIn for activity tracking. When users interact with application, they generate passive information like the clicks, the time spent on a particular page or other updates by the user. All the messages are published and can be consumed by applications to generate report.
5.2 Messaging
Kafka is an excellent choice for messaging systems. Its ability to handle high throughput, low latency, and durability makes it well-suited for delivering notifications like emails.
5.3 Logging
Kafka is an ideal platform for collecting, processing, and analyzing application and system metrics and logs. Applications publish metrics on a regular basis to a Kafka topic, and those metrics can be consumed by systems for monitoring and alerting.
5.4 Commit log
Kafka’s underlying commit log architecture facilitates the real-time streaming of database change events, providing a foundation for applications to consume and react to these updates.
5.5 Stream processing
Stream processing involves processing a continuous flow of incoming data as it arrives, rather than storing it for later batch processing. Kafka is ideally suited for this because it acts as a real-time data pipeline, delivering a continuous stream of records.
6. Kafka’s origin
Kafka was created to address the data pipeline problem at LinkedIn. It was designed to provide a high-performance messaging system that can handle many types of data and provide clean, structured data about user activity and system metrics in real time.
Jeff Weiner, former CEO of LinkedIn
The Kafka was developed at LinkedIn by a team led by Jay Kraps. Other team members were Neha Narkhede and Jun Rao. The primary goals were to:
- Decouple producers and consumers by using a push-pull model.
- Enable message data persistence within the messaging system to support access by multiple consumers.
- Optimize for high throughput of messages.
- Allow horizontal scaling of the system to accommodate growth as data streams expand.
The result was a publish/subscribe messaging system featuring a conventional messaging interface paired with a storage layer akin to a log-aggregation system.
Kafka was released as an open source project on GitHub in late 2010.
7. Conclusion
Kafka is a powerful, scalable, and distributed platform for handling real-time data streams.
As you delve deeper into Kafka, you’ll discover its immense potential in various domains such as IoT, financial systems, e-commerce, and more. Remember, Kafka is more than just a messaging system; it’s a platform for building real-time applications that can handle massive volumes of data.