1. Introduction
In this tutorial, we’ll get some hands-on experience with Kubernetes. This is going to be a long tutorial as we’ll discuss various concepts.
2. ‘kubectl run’ command
>kubectl run nginx --image=nginx pod/nginx created
The kubectl run command is used to start a new instance of an application in Kubernetes, which is typically done by creating a Pod that runs a specified container image. nginx is the name you’re giving to the new application or deployment. Kubernetes will create a pod running an instance of an NGINX container.
--image=nginx: Specifies the Docker image to use for this deployment, here nginx, which pulls the official NGINX image from Docker Hub.
To create a deployment, which is preferred for managing applications, you’d run something like:
kubectl create deployment nginx --image=nginx
This would create a deployment named “nginx” that Kubernetes can manage for scaling, updates, and self-healing.
3. Get Pods
The kubectl get pods command is used to list all the pods running in a Kubernetes cluster.
>kubectl get pods NAME READY STATUS RESTARTS AGE nginx 1/1 Running 0 3m29s
In the current state, nginx web server is not accessible to the external users. You can however access it internally inside the node. Later, when we’ll discuss about networking and services and we’ll discuss how to make this accessible to the external users.
4. Describe Pods
The command kubectl describe pods is used to get detailed information about one or more pods in a Kubernetes cluster. It shows comprehensive details, including the pod’s status, events, labels, annotations, and other metadata.
4.1 Syntax
kubectl describe pods [POD_NAME] -n [NAMESPACE]
- [POD_NAME]: Specify the name of the pod. If omitted, it describes all pods in the specified namespace.
- -n [NAMESPACE]: Specifies the namespace. If omitted, it defaults to the “default” namespace.
>kubectl describe pods
Name: nginx
Namespace: default
Priority: 0
Service Account: default
Node: docker-desktop/192.168.65.4
Start Time: Sat, 02 Nov 2024 23:12:45 +0530
Labels: run=nginx
Annotations: <none>
Status: Running
IP: 10.1.0.22
IPs:
IP: 10.1.0.22
Containers:
nginx:
Container ID: docker://b913309c8c2cf908b7c5eba260cc4bc8980b1e580813d5512d687652a04d88e9
Image: nginx
Image ID: docker-pullable://nginx@sha256:28402db69fec7c17e179ea87882667f1e054391138f77ffaf0c3eb388efc3ffb
Port: <none>
Host Port: <none>
State: Running
Started: Sun, 03 Nov 2024 10:13:47 +0530
Last State: Terminated
Reason: Error
Exit Code: 255
Started: Sat, 02 Nov 2024 23:12:52 +0530
Finished: Sun, 03 Nov 2024 10:13:30 +0530
Ready: True
Restart Count: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-zqjhz (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-zqjhz:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 11h default-scheduler Successfully assigned default/nginx to docker-desktop
Normal Pulling 11h kubelet Pulling image "nginx"
Normal Pulled 11h kubelet Successfully pulled image "nginx" in 4.7049646s (4.7050255s including waiting)
Normal Created 11h kubelet Created container nginx
Normal Started 11h kubelet Started container nginx
Normal SandboxChanged 48s kubelet Pod sandbox changed, it will be killed and re-created.
Normal Pulling 47s kubelet Pulling image "nginx"
Normal Pulled 44s kubelet Successfully pulled image "nginx" in 2.9922854s (2.9923243s including waiting)
Normal Created 44s kubelet Created container nginx
Normal Started 44s kubelet Started container nginx
When you run the kubectl with -o wide you get two additional fields IP and Node.
>kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx 1/1 Running 1 (3m5s ago) 11h 10.1.0.22 docker-desktop <none> <none>
IP is the IP address assigned to the Pod. Each Pod is assigned its own IP address.
>kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES nginx 1/1 Running 1 (3m5s ago) 11h 10.1.0.22 docker-desktop <none> <none>
5. Pods with a YAML file
Now, we’ll discuss about creating a Pod using a YAML based configuration file. We’ll learn how to write YAML files specifically for Kubernetes. Kubernetes uses YAML files as input for the creation of objects such as PODs, replicas, deployment services, etc. All of these follow similar structure. Kubernetes definition file always contains 4 top level fields:
apiVersionkindmetadataspec
These are required fields and you must have these in your file. Let us discuss these fields.
- apiVersion
TheapiVersionfield specifies the API version used to create the Kubernetes object. Kubernetes has multiple API groups and versions (such asv1,apps/v1,batch/v1, etc.), each offering a set of objects that support different levels of stability and features. Choosing the correctapiVersionensures compatibility with your cluster and access to specific features or resources.
Example:apiVersion: apps/v1
Example Valuesv1: Core API group, generally used for basic resources likePod,Service,ConfigMap.apps/v1: Often used for higher-level objects likeDeployment,DaemonSet,ReplicaSet.batch/v1: Used for objects likeJobandCronJobfor scheduling jobs.
- kind
Thekindfield defines the type of Kubernetes resource being created, such asPod,Service,Deployment, orJob. It tells Kubernetes what kind of object to instantiate and how to manage it.
Examplekind: Deployment
ExamplesPod: Defines a single instance of a containerized application.Service: Exposes a group of Pods to other services or external clients.Deployment: Manages a set of replicated Pods, handling rolling updates and scaling.ConfigMap,Secret: Used for injecting configuration data into Pods.
- metadata
The metadata section provides metadata about the Kubernetes object, like its name, namespace, labels, and annotations. This metadata is essential for organizing and managing resources within a cluster.
Fields- name: A unique name within the namespace. Required.
- namespace: Specifies the namespace the object belongs to (e.g.,
default,kube-system). If omitted, it defaults to thedefaultnamespace. - labels: Key-value pairs for organizing and selecting resources. Labels are frequently used by selectors to identify groups of resources.
- annotations: Key-value pairs used for storing non-identifying information. Annotations can store additional configuration data, which is typically used by other systems or tools.
metadata:
name: my-app
namespace: default
labels:
app: my-app
env: production
annotations:
owner: "team@example.com"
- spec
Thespecfield is where the actual specification of the Kubernetes object goes. Each type of object has a uniquespecstructure, tailored to define its behavior and desired state. The structure and fields ofspecvary significantly depending on the object type.
Examples by Object Type- Pod spec: Defines containers, their images, ports, volumes, and other configurations.
- Deployment spec: Specifies how many replicas of a Pod should be running, which images to use, update strategies, and selectors for identifying managed Pods.
- Service spec: Describes how the service should expose the underlying Pods, including ports, selectors, and the service type (ClusterIP, NodePort, LoadBalancer).
Example for a Deployment
In this example, the spec specifies that we want 3 replicas of a Pod running the nginx image, with a label selector that targets Pods labeled with app: my-app.
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx:1.17
ports:
- containerPort: 80
Full Example: Deployment YAML
Here’s a full example of a Deployment YAML configuration:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app-deployment
namespace: default
labels:
app: my-app
spec:
replicas: 3
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx:1.17
ports:
- containerPort: 80
6. Replication Controller
Replication controller helps us run multiple instances of a single Pod in the Kubernetes cluster thus providing high availability. Even if you have a single Pod, the replication controller can help by automatically bringing up a new Pod. Thus the replication controller ensures that the specified number of pods are running at all times. Another reason we need replication controller is to create multiple pods to share the load across. Replication controller spans across multiple nodes in the cluster. It helps us balance the load across multiple pods on different nodes as well as kill our application.
An another similar term is Replica Set. Both have the same purpose but they are not the same. Replication controller is the older technology that is being replaced by the Replica Set. Replica Set is the new recommended way to set up replication.
Let us not see how to create a Replication Controller. We’ll create a Replication Controller definition file and will name it rc-definition.yml.
apiVersion: v1
kind: ReplicationController
metadata:
name: myapp-rc
labels:
app: myapp
type: front-end
spec:
template:
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
replicas: 3
Following are important points about this file:
- There are 4 main sections,
apiVersion,kind,metadataandspec. - The
apiVersionis specfic to what we are creating. In this case replication controller is supported by Kubernetes versionv1. So we’ll set it asv1. kindisReplicationController.- In the
metadata, we’ll call itmyapp-rcand will add few more labelsappandtype. - The
specsection defines what is inside the object we are creating. In this case ReplicationController creates multiples of Pod. We create a template section under ‘spec’ to provide a Pod template to be used by the ReplicationController to create replicas. We have already seen earlier how to create a Pod using the YAML file. - To specify the replicas, provide a section
replicasunderspec. Remember,templateandreplicasare direct children ofspec.
Once the file is ready, run kubectl create command with the file name:
kubectl create -f rc-definition.yml
> kubectl create -f rc-definition.yml replicationcontroller/myapp-rc created
To view the list of created replication controllers, use kubectl get command:
>kubectl get replicationcontroller NAME DESIRED CURRENT READY AGE myapp-rc 3 3 3 2m11s
To view the list of pods created by replication pods, use kubectl get pods command:
>kubectl get pods NAME READY STATUS RESTARTS AGE myapp-rc-dgqzh 1/1 Running 0 3m45s myapp-rc-fr24x 1/1 Running 0 3m45s myapp-rc-s5dqx 1/1 Running 0 3m45s nginx 1/1 Running 1 (178m ago) 13h
Note that all these pods’ name is starting with the name of the replication controller myapp-rc indicating that these are created automatically created by replication controller.
Let us now see the ReplicaSet.
7. ReplicaSet
Creating a ReplicaSet is very similar to replication controller.
- The selector section helps the replica set identify what parts fall under it. But why would you have to specify what pods fall under it. If we have provided the contents of the pod definition file itself in the template it’s because replica set can also manage pods that were not created as part of the replica set creation. For examples there were pods created before the creation of the replica set that match labels specified in the selector the replica set will also take those pods into consideration when creating the replicas.
- The
matchLabelsselector simply matches the labels specified under it to the labels on the pod.
To create a replica set use kubectl create command.
>kubectl create -f replicaset-definition.yml replicaset.apps/myapp-replicaset created
To get the replica set use kubectl get replicaset command:
>kubectl get replicaset NAME DESIRED CURRENT READY AGE myapp-replicaset 3 3 3 115s
To get the pods, use kubectl get pods command:
>kubectl get pods NAME READY STATUS RESTARTS AGE myapp-rc-dgqzh 1/1 Running 0 75m myapp-rc-fr24x 1/1 Running 0 75m myapp-rc-s5dqx 1/1 Running 0 75m myapp-replicaset-7867l 1/1 Running 0 2m59s myapp-replicaset-gj7vc 1/1 Running 0 2m59s myapp-replicaset-lf7c5 1/1 Running 0 2m59s nginx 1/1 Running 1 (4h10m ago) 15h
8. Labels and Selectors
Let us understand the need of labels and selectors with an example. Suppose we deployed three instances of our frontend application as three pods. We would like to create a replication controller or replica set to ensure that we have three active pods at any time. You can use replica sets to monitor existing pods if these were already created. In case they were not created, the replica set will create these for you. The role of the replica set is to monitor the pods and if any of these were to fail, deploy new ones. The replica set is in fact a process that monitors the pods. There could be hundred of other pods in the cluster running different applications.
This is where labelling our pods during creation comes in handy. We could now provide these labels as a filter for replica set under the selector section we use to match labels filter and provide the same label that we used while creating the pods. This way the replica set knows which pods to monitor.
9. Scaling
Suppose we need to scale it to 6 replicas.
The first way is to update the number of replicas in the definition file to 6. Then run the kubectl replace command to specify the same file using the -f parameter and that will update the replicaset to have six replicas.
>kubectl replace -f replicaset-definition.yml
The second way to do it is to run the kubectl scale command.
>kubectl scale --replicas=6 -f replicaset-definition.yml
Note that the this command will not update the replicas in the file.
You can also provide the replica set name in the command.
> kubectl scale --replicas=6 replicaset myapp-replicaset
11. Deployment
A Deployment in Kubernetes is a resource object that provides a higher-level way to manage and control applications running as containers in a cluster. It simplifies tasks like scaling, updating, and rolling back applications. The Deployment controller automatically manages replica Pods, ensuring a specified number of instances are running, and enabling rolling updates for smoother releases.
11.1 Key Features of Deployment
- Declarative Updates: Deployments allow you to declare the desired state of an application, including the number of replicas, container images, and other configurations.
- Scaling: With Deployments, you can easily scale your application up or down by adjusting the replica count.
- Rolling Updates and Rollbacks:
- Rolling Updates: When updating an application (e.g., changing the container image version), Kubernetes gradually replaces old Pods with new ones, ensuring minimal downtime.
- Rollbacks: If a Deployment update causes issues, you can easily roll back to a previous working state.
- Self-Healing: Deployments automatically replace failed or unhealthy Pods to maintain the desired state.
- Selector and Labels: Deployments use label selectors to identify and manage the Pods they control. This enables fine-grained control over specific subsets of Pods.
This is how you create a Deployment:
>kubectl create -f deployment-definition.yml deployment.apps/myapp-deployment created
To get deployments:
>kubectl get deployments NAME READY UP-TO-DATE AVAILABLE AGE myapp-deployment 3/3 3 3 58s
Deployment has created the replicaset. This can be verified:
>kubectl get replicaset NAME DESIRED CURRENT READY AGE myapp-deployment-6ff5f7d548 3 3 3 80s
>kubectl get pods NAME READY STATUS RESTARTS AGE myapp-deployment-6ff5f7d548-9z8px 1/1 Running 0 2m4s myapp-deployment-6ff5f7d548-cqwth 1/1 Running 0 2m4s myapp-deployment-6ff5f7d548-fqrg6 1/1 Running 0 2m4s
12. kubectl get all
The kubectl get all command is used to list and view the current status of all Kubernetes resources within a namespace. It provides a snapshot of the resources running in the cluster, including their names, statuses, and other summary information.
>kubectl get all NAME READY STATUS RESTARTS AGE pod/myapp-deployment-6ff5f7d548-9z8px 1/1 Running 0 3m47s pod/myapp-deployment-6ff5f7d548-cqwth 1/1 Running 0 3m47s pod/myapp-deployment-6ff5f7d548-fqrg6 1/1 Running 0 3m47s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d3h NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/myapp-deployment 3/3 3 3 3m47s NAME DESIRED CURRENT READY AGE replicaset.apps/myapp-deployment-6ff5f7d548 3 3 3 3m47s
13. Rollout and Versioning in Deployment
When you create a deployment, it triggers a rollout. A new rollout creates a new Deployment revision. Let’s call it revision 1. In the future when the application is upgraded, i.e. the container version is updated to a new one a new rollout is triggered and a new deployment revision is created named revision 2. This helps us keep track of the changes made to our deployment and enables us to rollback to a previous version of deployment if necessary.
You can see the status of your rollout by running the kubectl rollout status deployment/myapp-deployment.
To see the revisions and history of the deployment use kubectl rollout history command.
>kubectl rollout history deployment/myapp-deployment deployment.apps/myapp-deployment REVISION CHANGE-CAUSE 1 <none>
13.1 Rollout Strategies
There are two types of deployment strategies. For example, if you have five replicas of your web application instance deployed. One way to upgrade these to a newer version is to destroy all of these and then create newer version of application instances. Meaning first destroy the five running instances and then deploy five new instances of the new application. The problem with this is that during the period after the older versions are down and before a newer version is up, the application is down and inaccessible to uers. This strategy is known as the recreate strategy. This is not the default strategy.
The second strategy is where we do no destry all at once. Instead we take down the older version and bring a newer version one by one. This way the application never goes down and the upgrade is seemless. This strategy is calling rolling update. Rolling update is the default deployment strategy.
Note: In the recreate strategy, the replicaset is set to 0 and then scaled back. In the rolling update, the old replica set is scaled down one at a time.
Following is an example of RollingUpdate strategy.
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
labels:
app: example
spec:
replicas: 3
strategy:
type: RollingUpdate
rollingUpdate:
maxUnavailable: 1
maxSurge: 1
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
- name: example-container
image: nginx:1.17 # Initial image version
ports:
- containerPort: 80
Following is an example of Recreate strategy:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
labels:
app: example
spec:
replicas: 3
strategy:
type: Recreate
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
- name: example-container
image: nginx:1.17 # Initial image version
ports:
- containerPort: 80
13.2 How do we apply the update?
Once we make the necessary changes in the deployment definition file, like changing the image version, run kubectl apply command to apply the changes.
>kubectl apply -f deployment-definition.yml
Rollout is triggered and a new revision of deployment is created.
You can undo a rollout using the kubectl rollout undo command.
> kubectl rollout undo deployment/myapp-deployment
The deployment will then destroy the pod in the new replica set and bring the older ones up in the old replica set.
14. Networking in Kubernetes
In Docker, IP address is assigned to the container. In Kubernetes, the IP address is assigned to the Pod. When Kubernetes is initially configured we create an interal private network and all pods are attached to it. When we deploy multiple pods they all get a separate IP address assigned from this network. The Pods can communicate with each other using this IP but access to the other internal Pods using this IP may not be a good idea as Pods are deleted and recreated.
Kubernetes expects us to set up networking to meet certain fundamental requirements. Some of these are that all the containers are pods in a Kubernetes cluster must be able to communicate with one another without having to configure NAT. All nodes must be able to communicate with containers and all containers must be able to communicate with the nodes in the cluster. Kubernetes expects us to set up a networking solution that meets these criteria. Luckily, we don’t have to set it all up ourselves because there are several pre-built solutions available. Some of these are the Cisco SCI networks, cilium, flannel, Calico etc. Depending on the platform you’re deploying your Kubernetes cluster on, you may use one of these solutions. For example if you were setting up a kubernetes cluster from scratch on your own systems you may use any of the solutions like Calico or Flannel. If you were deploying on a VMware environment and NSX-T may be a good option. Depending on your environment and after evaluating the pros and cons of each of these you may choose the right networking solution.
15. Kubernetes Services
Kubernetes enables communication between various components within and outside an application. Kubernetes services helps us connect applications together with other applications and users.
For instance, our application is organized into groups of Pods that handle different functions: one group serves the frontend to users, another manages backend processes, and a third connects to an external data source. Services facilitate connectivity between these groups, allowing the frontend to be accessible to end users, enabling communication between backend and frontend Pods, and establishing links to external data sources. In this way, services provide loose coupling between the microservices in our application.
Let’s dive into an example to understand services in Kubernetes. Until now, we’ve discussed how pods connect internally within a cluster. Now, let’s turn our attention to external networking.
Suppose we’ve deployed a pod running a web application. How can we, as external users, access this application?
First, let’s examine the network setup. The Kubernetes node has an IP address of 192.168.1.2, and my laptop, on the same local network, has an IP of 192.168.1.10. Meanwhile, the pod is on an internal network with an IP range starting at 10.244.0.0, specifically assigned IP 10.244.0.2. Since this pod IP isn’t on our local network, we can’t directly connect to it. One option to view the web page would be to SSH into the Kubernetes node (192.168.1.2) and access the pod from there. We could use curl or, if the node has a GUI, open a browser and navigate to the pod’s IP (https://10.244.0.2). However, this only gives us access from within the Kubernetes node.
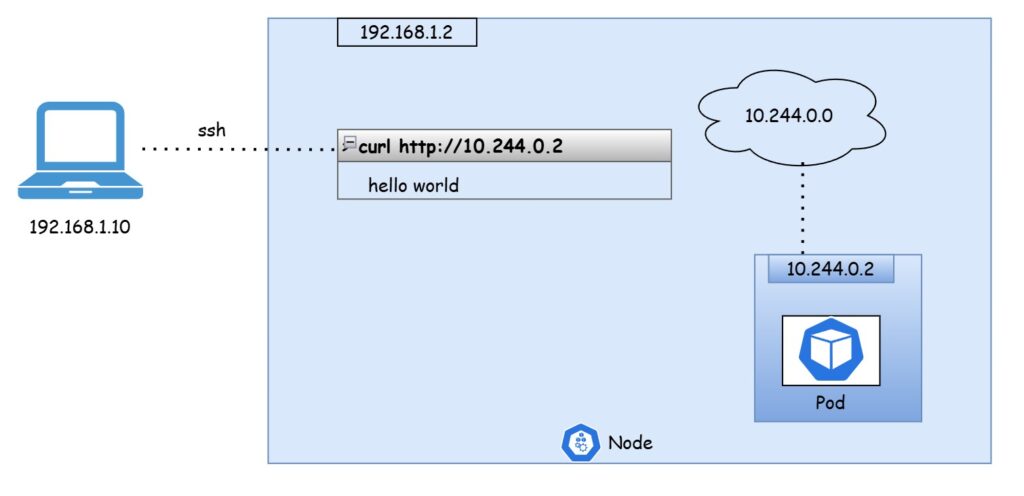
To access the web server directly from our laptop without needing to SSH into the Kubernetes node, we need a way to route requests to the pod from the node itself. Ideally, we could just use the Kubernetes node’s IP directly. However, since the pod is in a different internal network, we need an intermediary that can handle this communication.
This is where a Kubernetes service comes into play. A Kubernetes service acts as a bridge, allowing external traffic to reach the pod. Like other Kubernetes objects—such as pods, replica sets, and deployments—a service is used to define routing rules. One of its core functions is to listen on a specific port on the node and forward requests from that port to the target port on the pod, allowing seamless access to the application from outside the cluster.
For our web application, we’re using a NodePort service. This type of service exposes a port on each node, directing any traffic received on that port to the appropriate pods, making it accessible from outside the cluster. Beyond NodePort, there are several other service types in Kubernetes, each with its own unique function:
- NodePort: This is what we’re using to make an internal pod accessible through a node’s port.
- ClusterIP: This type creates a virtual IP within the cluster to enable seamless communication between services. For example, it allows front-end and back-end servers within the cluster to connect with each other.
- LoadBalancer: This service type is useful when working with supported cloud providers. It provisions an external load balancer, allowing for efficient distribution of incoming traffic across multiple web servers in a front-end tier.
Let’s revisit the NodePort service that we discussed earlier, focusing on the details of how it maps external access to the web application. In this setup, there are three key ports involved:
- Target Port: This is the port on the pod where the actual web server is running (in this case, port 80). It’s called the target port because the service forwards incoming requests to this port on the pod.
- Service Port: This is the port exposed by the service itself. It’s simply referred to as the port. From the service’s perspective, this is the entry point that receives external traffic and then redirects it to the target port on the pod.
- Node Port: This is the port on the node that external users will connect to in order to access the service. In this case, it’s set to 30008. NodePort services only allow ports in the range of 30000 to 32767, which is why this port is automatically assigned within that valid range.
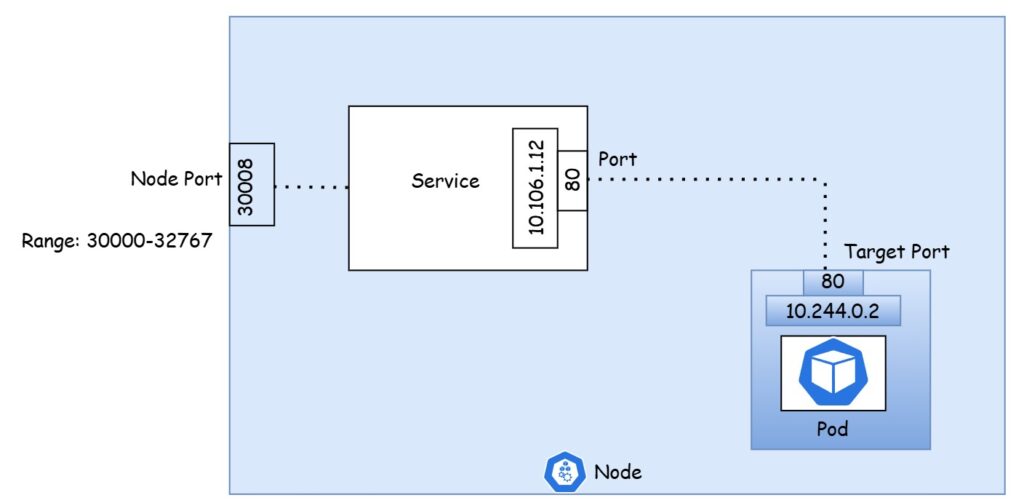
To sum up, the service acts as a virtual server with its own internal cluster IP, and it maps the external traffic from the node port to the service port, which in turn forwards it to the target port on the pod running the web application.
Let’s go through the process of creating a service in Kubernetes, similar to how we’ve created deployments, replica sets, and pods in the past. We’ll define the service using a YAML configuration file, and the structure of this file will be similar to the other Kubernetes object files we’ve worked with. It will contain the usual sections: API version, kind, metadata, and spec.
- API Version: We’ll set this to
v1since we are using a standard service definition. - Kind: This will be set to
Serviceto indicate that we are creating a service object. - Metadata: This section will contain the name of the service, which should be unique, but labels are optional for now.
The most critical part of the file, as always, is the spec section. This is where we define the specific details of the service we’re creating, and where it differs based on the object type. For a service, the spec includes several important subsections, including type and ports.
Type: This defines the kind of service we are setting up. It could be ClusterIP, NodePort, or LoadBalancer. Since we are setting up a NodePort service, we’ll specify the type as NodePort.
Ports: This section defines the port mappings for the service:
- Target Port: This is the port on the pod where the application is running. We’ll set it to port 80.
- Port: This is the port exposed on the service. We will also set this to 80 to match the pod’s target port.
- Node Port: This is the external port on the node used for accessing the service. We’ll set this to a valid number, such as 30008 (within the valid range of 30000 to 32767).
It’s important to note that the port field is mandatory. If we don’t specify a target port, it defaults to the same value as the service port. If we don’t specify a node port, Kubernetes will automatically allocate one within the valid range.
At this point, we’ve defined the service ports, but there’s one crucial detail missing: the connection between the service and the pod. While we’ve specified the target port, we haven’t defined which pod should be targeted. In a cluster, there could be many pods running on the same port, so we need a way to ensure the service directs traffic to the correct pod.
To make this connection, we use labels and selectors, a common technique in Kubernetes. In the pod definition, we would have already assigned a label to the pod. Now, we need to refer to this label in the service definition to bind the service to the correct pod.
In the spec section of the service definition file, we add a new field called selector. This is where we define the labels that match the pod. The labels we use here should correspond to those defined in the pod’s configuration. By including the correct labels in the selector, the service will route traffic to the correct pod.
Once the definition file is ready with the appropriate labels and selectors, we can create the service by running the following command:
kubectl create -f service-definition.yaml
This will create the service and link it to the pod based on the label selector, enabling external access to the application through the NodePort. Now that the service has been created, you can verify its existence by running the following command:
kubectl get services
This will list the services in your cluster, showing the cluster IP, the mapped ports, and the service type, which in this case is NodePort. The port on the node is set to 30008, as specified in the service definition file. This means you can now access the web service using this port, either through curl or a web browser. For instance, you can run:
curl 192.168.1.2:30008
where 192.168.1.2 is the IP address of the node and 30008 is the NodePort we defined in the service file. This will allow you to access the web service directly.
So far, we’ve discussed a service mapped to a single pod. But in production environments, it’s rare to have just one pod running your application. Typically, you’ll have multiple pods for higher availability and load balancing.
In this scenario, you might have several pods running identical instances of your web application. All these pods share the same label, for example, app: myapp. This label is used as a selector when creating the service. The service automatically discovers all the pods with the matching label, so if there are three pods running, the service will route traffic to all three.
Kubernetes uses a random algorithm to load-balance requests between these pods, which means the service effectively acts as a built-in load balancer. There’s no additional configuration required to achieve this; the service automatically handles the distribution of traffic across the available pods.
Now, what happens if the pods are distributed across multiple nodes? In this case, you might have your web application running on different nodes within the cluster. When you create the service, Kubernetes automatically ensures that the service spans across all nodes in the cluster. It maps the target port to the same node port on each node, so regardless of which node you send requests to, they’ll be forwarded to the correct pod.
For example, you can access your application by using the IP of any node in the cluster, and the same port number (30008 in this case) will be available on all the nodes. If you curl the IP of different nodes using port 30008, you’ll reach the same service, with traffic being forwarded to the appropriate pod based on the load-balancing strategy.
To summarize, regardless of the scenario—whether you have a single pod on a single node, multiple pods on one node, or multiple pods spread across multiple nodes—the service creation process is the same. Kubernetes automatically handles the mapping and distribution of traffic to the correct pods, adapting to changes like adding or removing pods. Once created, the service remains highly flexible and dynamic, requiring no additional configuration.
apiVersion: v1
kind: Service
metadata:
name: myapp-service
spec:
type: NodePort
ports:
- targetPort: 80
port: 80
nodePort: 30008
selector:
app: myapp
type: front-end