1. What is a Kubernetes Pod?
Pods are the smallest deployable units of computing that you can create and manage in Kubernetes. A Pod is a group of one or more containers, with shared storage and network resources, and a specification for how to run the containers.
Each Pod is a shared execution environment for one or more containers. The execution environment includes a network stack, volumes, shared memory, and more. Containers in a single-container Pod have the execution environment to themselves, whereas containers in a multi-container Pod share it.
A Pod’s contents are always co-located and co-scheduled, and run in a shared context. A Pod serves as an application-specific “logical host,” encapsulating one or more closely integrated application containers. You need to install a container runtime into each node in the cluster so that Pods can run there. A Pod’s shared context includes a combination of Linux namespaces, cgroups, and other isolation mechanisms similar to those used to isolate containers. Within this shared context, individual applications can have additional layers of isolation. Essentially, a Pod is akin to a collection of containers that share namespaces and filesystem volumes.
Pods in a Kubernetes cluster are used in two main ways:
- Pods that run a single container. The “one-container-per-Pod” model is the most common Kubernetes use case; in this case, you can think of a Pod as a wrapper around a single container; Kubernetes manages Pods rather than managing the containers directly.
- Pods that run multiple containers that need to work together. A Pod can encapsulate an application composed of multiple co-located containers that are tightly coupled and need to share resources. These co-located containers form a single cohesive unit.
Multi-container Pods also help us implement the single responsibility principle where every container performs a single simple task.
There are powerful use cases for multi-container Pods, including:- Service meshes
- Helper services that initialize app environments
- Apps with tightly coupled helper functions such as log scrapers
Note: Kubernetes marks a Pod as running when all its containers are started. For example, if a Pod has two containers and only one is started, the Pod is not ready.
Here is what you do when you deploy an application:
- You create an app.
- You containerize the app.
- You push it to the registry.
- You wrap it in a pod.
- You give the pod to Kubernetes.
- Kubernetes runs the pod.
Layers are added and each layer adds something:
- The container wraps the app and provides dependencies.
- The Pod wraps the container so that it runs on Kubernetes.
- The Deployment wraps the Pod and adds self-healing, scaling and more.
2. Pods are an abstraction layer
Pods abstract the details of different workload types allowing you to run containers, virtual machines, serverless functions, and WebAssembly (Wasm) applications within them. Kubernetes treats all these workloads uniformly, without distinguishing between them.
This abstractions helps Kubernetes as Kubernetes can focus on deploying and managing pods without caring what’s inside them.
Following is the redacted output of kubectl explain pods --recursive:
> kubectl explain pods --recursive
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
FIELDS:
apiVersion <string>
kind <string>
metadata <ObjectMeta>
annotations <map[string]string>
creationTimestamp <string>
deletionGracePeriodSeconds <integer>
deletionTimestamp <string>
finalizers <[]string>
generateName <string>
generation <integer>
labels <map[string]string>
managedFields <[]ManagedFieldsEntry>
apiVersion <string>
fieldsType <string>
You can drill down into specific Pod attributes like the following:
>kubectl explain pod.spec.restartPolicy
KIND: Pod
VERSION: v1
FIELD: restartPolicy <string>
DESCRIPTION:
Restart policy for all containers within the pod. One of Always, OnFailure,
Never. In some contexts, only a subset of those values may be permitted.
Default to Always. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
Possible enum values:
- `"Always"`
- `"Never"`
- `"OnFailure"`
3. Pods enable resource sharing
Pods run one or more containers, and all containers in the same Pod share the Pod’s execution environment. This includes:
- Shared filesystem and volumes (mnt namespace)
- Shared network stack (net namespace)
- Shared memory (IPC namespace)
- Shared process tree (pid namespace)
- Shared hostname (uts namespace)
Following figure shows a multi-container Pod with both containers sharing Pod’s volume and network interface:
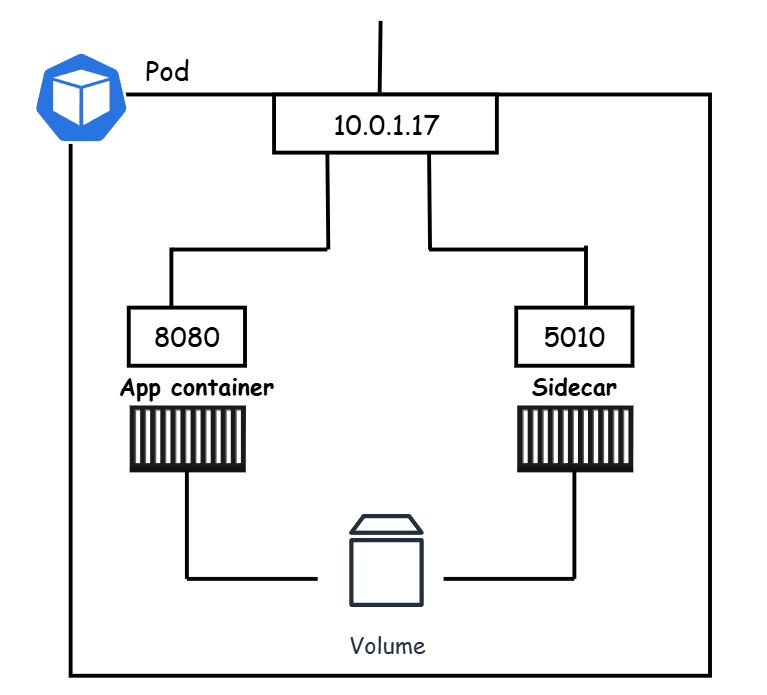
Other applications and clients can reach the containers using the Pod’s IP address (10.0.10.17). The main application container is accessible on port 8080, while the sidecar is on port 5010. For internal communication within the Pod, they can utilize the Pod’s localhost adapter. Both containers also share the Pod’s volume, enabling them to exchange data seamlessly.
4. Pods and scheduling
Kubernetes ensures that all containers within a Pod are scheduled to the same cluster node. However, you should only place containers in the same Pod if they need to share resources like memory, volumes, and networking. If your goal is simply to co-locate two workloads on the same node, it’s better to put them in separate Pods and use one of the following strategies to schedule them together.
Pods provide lot of scheduling features. Here, we’ll discuss the following:
- nodeSelectors
- Affinity and anti-affinity
- Topology spread constraints
- Resource requests and resource limits
nodeSelectors
nodeSelectors are the most straightforward method to schedule Pods on specific nodes. By assigning a list of labels to the nodeSelector, the scheduler will place the Pod only on nodes that have all the specified labels.
Affinity and anti-affinity rules
A hard node affinity rule with the project=abc label instructs the scheduler to run the Pod exclusively on nodes that have this label. If no such node is found, the Pod won’t be scheduled. With a soft rule, the scheduler attempts to find a node with the project=abc label but will still schedule the Pod elsewhere if necessary. An anti-affinity rule, on the other hand, directs the scheduler to avoid nodes with the project=abc label.
Topology spread constraints
Topology spread constraints offer a flexible method to distribute Pods across your infrastructure, ensuring availability, performance, locality, or other specific requirements. A common use case is distributing Pods across different availability zones in your cloud or datacenter to achieve high availability (HA). Additionally, you can define custom domains for various purposes, such as placing Pods closer to data sources, improving network latency by situating them near clients, and other strategic reasons.
Resource requests and resource limits
Resource requests and limits are crucial, and every Pod should define them. They inform the scheduler about the CPU and memory requirements of a Pod, enabling it to choose nodes with adequate resources. Without these specifications, the scheduler cannot determine the necessary resources for a Pod and might assign it to a node lacking sufficient resources.
5. Pod lifecycle
Pods are immutable. Once a Pod executes a task, then it terminates. Once it is complete, it can not be restarted. If a pod fails, it gets deleted and cannot be restarted.
Immutable means you cannot modify them after they’re deployed. For persistent data storage, attach a volume to the Pod and store the data there to prevent data loss when the Pod is deleted. A Pod remains in the running phase indefinitely if it’s a long-lived Pod, such as a web server.
For short-lived Pods, like those used for batch jobs, they reach the succeeded state as soon as all their containers have completed their tasks successfully.
6. Pod restart policies
Kubernetes can’t restart Pods, it can definitely restart containers. This is
done by the local kubelet and governed by the value of the spec.restartPolicy, which can be any of the following:
- Always
- Never
- OnFailure
The policy applies to all containers in the Pod except for init containers.
Long-running containers are used to host applications like web servers, data stores, and message queues that are meant to operate continuously. If these containers fail, they generally need to be restarted. Therefore, they are usually configured with an Always restart policy.
Short-lived containers usually handle batch-style workloads, running tasks until they are completed. Generally, you’ll be satisfied when these tasks finish, and you’ll only want to restart the containers if they fail. Thus, assigning them the OnFailure restart policy is appropriate. If you don’t mind if they fail, you can set the Never policy.
When we say restart the Pod, we mean replace it with a new one.
7. The declarative model of Kubernetes
You post the Deployment (YAML file) to the API server as the desired state of the application, and Kubernetes implements it. The declarative model of Kubernetes operates on three basic principles:
- Observed state: the state you have
- Desired state: the state you want
- Reconciliation: process of keeping observed state in sync with desired state
In Kubernetes, the declarative model can be explained with the help of following points:
- Define the desired state of your application in a YAML manifest file. This includes details such as the container images to use, the number of replicas, and the network ports.
- Submit this YAML file to the API server. The most common way of posting the YAML file to the API server is the
kubectlcommand-line utility. On the API server, the YAML file is authenticated and authorized. - The cluster store logs it as an intent. At this point the desired state does not match the new desired state.
- A controller detects any difference between the current state and the new desired state.
- The controller makes the necessary changes to reconcile the differences. This process entails implementing all the modifications outlined in the YAML file, which typically involves scheduling new Pods, pulling container images, starting containers, connecting them to networks, and initiating application processes. Once reconciliation is completed, observed state will match desired state.
- The controller continuously runs in the background to ensure the observed state matches the desired state.
Note: Kubernetes supports both imperative model and declarative model but prefers the declarative model. The imperative model in Kubernetes involves directly issuing commands to manage the state of your resources. With this approach, you specify exactly what actions to take, such as creating, updating, or deleting resources.
8. Pod Scheduling
It is not easy to share memory, networking, and volume across nodes. Since, Pods are a shared execution environment, all containers in a Pod are always scheduled to the same node.
9. Pod – The unit of scaling
In Kubernetes, Pods are the smallest unit of scheduling. When you scale an application up, you add more Pods, and when you scale it down, you remove Pods. Scaling does not involve adding additional containers to existing Pods. When a new Pod is created, it gets a new ID and a new IP.
10. Pods are immutable
Pods are immutable. This means you never change them once they’re running. If you need to change or update a Pod, always replace it with a new one that includes the updates. You should never log into a Pod and make changes. When we talk about “updating Pods,” it always means deleting the old one and replacing it with a new one.
- Rollouts replace old Pods with new ones with new IPs
- Scaling up adds new Pods with new IPs
- Scaling down deletes existing Pods.
11. Deployments
While Kubernetes manages workloads using Pods, they are typically deployed through higher-level controllers such as Deployments, StatefulSets, and DaemonSets. These controllers run on the control plane and continuously monitor the state of the cluster, ensuring the observed state matches the desired state. Deployments, in particular, provide features like self-healing, scaling, rolling updates, and versioned rollbacks for stateless applications.
12. Pod Network
Every Kubernetes cluster operates a pod network that automatically connects all Pods. This network is typically a flat Layer-2 overlay, spanning all cluster nodes and enabling direct communication between Pods, regardless of whether they are on the same node or different ones.
The pod network is set up using a third-party plugin that integrates with Kubernetes and manages the network through the Container Network Interface (CNI). You select a network plugin when you build the cluster, and it configures the Pod network across the entire cluster. There are many plugins available, each with its own advantages and disadvantages. Currently, Cilium6 is among the most popular, offering advanced features such as enhanced security and observability.
The network is only for Pods and not nodes. You can connect nodes to multiple different networks; however, the Pod network spans all of them.
13. Kubernetes Services
In case of rollouts, scaling up and scaling down, clients can not make reliable connections to the individual pods. This is because new Pods with new IPs can be created and existing Pods can be deleted. This is when Kubernetes Services help by providing reliable networking for group of Pods.
Services in Kubernetes can be understood as having two main components: the front end and the back end. The front end is responsible for providing a consistent DNS name, IP address, and network port, making it easily accessible to clients. The back end, on the other hand, utilizes labels to distribute incoming traffic across a changing set of Pods, automatically balancing the load as needed.
As the application scales, undergoes updates, or experiences Pod failures, the Service actively maintains a list of healthy Pods. This dynamic list allows the Service to route traffic only to active, functional Pods, ensuring continuous and reliable operation. One of the key benefits of Services is that they guarantee stability in the DNS name, IP address, and network port on the front end, so these details remain unchanged, providing a consistent point of access.
14. Multi-container Pods
Sometimes it is beneficial to put two tightly coupled containers in the same Pod.
Kubernetes has two main patterns for multi-container Pods: init containers and sidecar containers.
14.1 Multi-container Pods: Init containers
Init containers are a specialized type of container defined in the Kubernetes API. They are run within the same Pod as application containers, but with a unique distinction: Kubernetes ensures that init containers start and finish before the main application container begins running, and they are guaranteed to run only once.
The primary purpose of init containers is to prepare and initialize the environment for the application containers. Let’s explore a couple of quick examples to illustrate their use:
- Remote API Check: Suppose you have an application that should only start when a remote API is ready to accept connections. Instead of complicating the main application with the logic to check the remote API, you can encapsulate this logic within an init container. When you deploy the Pod, the init container launches first, sending requests to the remote API and waiting for a response. During this time, the main application container remains inactive. Once the remote API responds, the init container completes its task, and only then does the main application container start.
- Repository Cloning: Consider another scenario where an application needs to clone a remote repository before starting. Instead of burdening the main application with the code to handle cloning and preparing the content (e.g., remote server address, certificates, authentication, file synchronization protocol, checksum verification, etc.), you can place this logic in an init container. The init container will complete this one-time task before the main application container begins running.
Despite their usefulness, init containers have a limitation: they are restricted to performing tasks before the main application container starts. If you need something that runs alongside the main application container, you should use a sidecar container instead.
14.2 Multi-container Pods: Sidecars
Sidecar containers are standard containers that run alongside application containers throughout the entire lifecycle of the Pod. Unlike init containers, sidecars are not a defined resource in the Kubernetes API. Currently, we use regular containers to implement the sidecar pattern, though efforts are underway to formalize this pattern in the API, and it is currently an early alpha feature.
The purpose of a sidecar container is to enhance an application by adding functionality without modifying the application itself. Common uses of sidecar containers include log scraping, syncing remote content, brokering connections, and data munging. They are also extensively used in service meshes to intercept network traffic, providing traffic encryption, decryption, and telemetry.
An example would be a multi-container Pod with a primary application container and a service mesh sidecar. The sidecar intercepts all network traffic, encrypts and decrypts it, and sends telemetry data to the service mesh control plane.